Hyperparameter Tuning
Tuning process
There are a lot of different hyperparameter that we need to tune. However, we need to realize that not all of them are of similar importances. Below are the hyperparameters ordered from the most important to the least important: 1. alpha 2. beta (default to 0.9), number of hidden unit, mini batch size 3. number of layer, learning rate decay 4. beta1, beta2, epsilon (if we use Adam optimization)
Don't use grid search
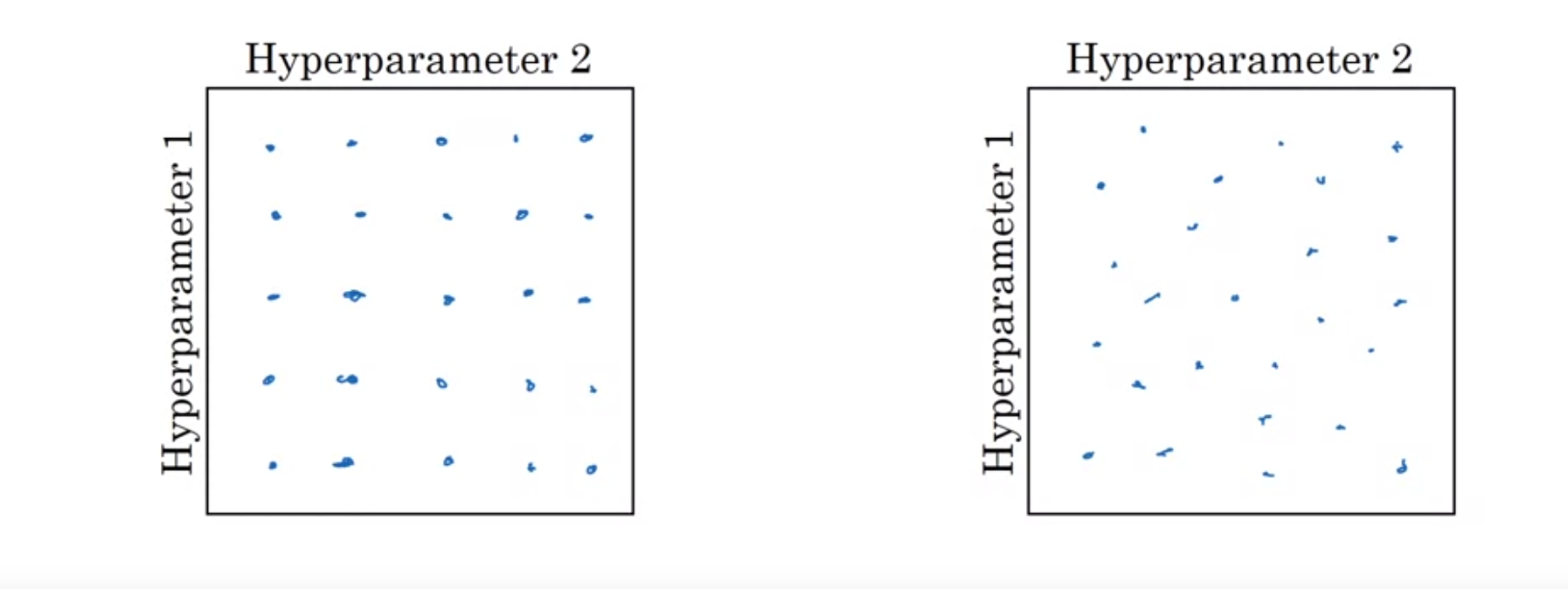
When you're searching for hyperparameter values, don't use grid search as shown on the bottom left. Instead use random search as shown on the right. It is because, not all hyperparameters have same importance. If we use grid search, we may only sample a few values for a hyperparameter that's important. With random search, we will sample a lot more values for those important hyperparameters.
Coarse to fine
After we randomly sample some hyperparameters' value, we may find region in the grid where those hyperparameters perform well. Then, we can perform search with higher dense on those sliced region.
Using an appropriate scale to pick hyperparameters
Sampling at random doesn't mean sampling uniformly at random. For some hyperparameters and ranges, it may makes sense to sampling uniformly. For example, number of hidden unit at a layer, between 50 - 100 or number of layer, among 2, 3, or 4.
However, for learning rate, which varies from 0.0001 to 1, sampling uniformly is not a good idea since most value sampled will be between 0.1 and 1. The right way of doing it would be:
r = -4 * np.random.rand()alpha = 10^r
In this case, r will be between [-4,0], thus alpha will be between [0.0001, 1].
Hyperparameters for exponentially weighted averages
beta = 0.9 ... 0.999
0.9 -> averaging over last 10 values
0.999 -> averaging over last 1000 values.
Thus, it doesn't makes sense to sample linearly.
So instead, we sampe using 1 - beta which ranges from 0.001 to 0.1 the way we did before.
r is uniformly sampled between [-3, -1], then, beta = 10^r.
In this way, we will spend same effort between 0.001 to 0.01 and 0.01 to 0.1.
Hyperparameter tuning in practice: pandas vs caviar
People in ML usually try different approach for their machine learning problems. Sometimes algorithm that do well for speech problems can be adopted to do well in NLP. Therefore, ML engineers need to try different models and keep reevaluating their ways of working by reading lots of papers in different ML domain.
Panda approach: Babysitting one model
Try one model, wait, if it works well, update the learning rate, otherwise try other model. This is usually done if we have limited computational resources.
Caviar approach: Training many models in parallel
Train a few model at once and see how they perform. There is no need to pay attention to a model, just hope that there are a few that do well.